Overview
Documentation of manual and automated LinkedIn data scraping, preparation, and analysis procedures. This method will allow you to scrape hundreds to thousands of LinkedIn posts at a time.
Background
According to a report from the Pew Research Center published in May, the majority of Twitter users in the U.S. have taken a break from the platform since Elon Musk’s takeover of the site. This is consistent with recent data from SimilarWeb in April, which reported a 7.3% decrease in web visits and a 9.8% decrease in daily active app users year-over-year.
Where are Twitter users flocking to, particularly in the U.S.MedEd community? Many users initially jumped ship to alternatives like Mastodon, which was short-lived. The new kid on the block is Meta’s Threads, which displaced 100M Twitter users in just a week, but it’s too early to draw any conclusions. Despite recent controversies, Reddit and TikTok remain strong social networks, but their user bases are too niche. Then there’s LinkedIn, which self-proclaims as the leading platform for B2B lead generation. According to a recent report, decision makers statistically represent 80% of its 900M+ members.
Although there is no definitive replacement for Twitter, we believe that LinkedIn is a strong candidate to become the new home of theMedEd community for the following reasons:
- Strong growth and platform ownership. While Twitter’s engagement levels decline, LinkedIn is experiencing record-level 18% user session growth. With strong backing from Microsoft, we don’t see LinkedIn going away anytime soon.
- User demographics closely align with theMedEd audience. The majority of LinkedIn users in the U.S. are males aged 30-39 (with the 40-49 age group coming in second), who hold at least a bachelor’s degree and earn more than $75K per household.
- Through our own social listening reports, we have observed numerousMedEd discussions held on LinkedIn by key stakeholders, including companies, executives, researchers, and HCPs. They share engaging patient cases videos, celebrate milestones with partners and colleagues, and announce late-breaking trial data during industry conferences using this platform.
Challenge
Current social listening tools, such as Netbase and Linkfluence, lack the ability to extract data from LinkedIn due to its closed social network. As a result, analyzing unowned LinkedIn content becomes a manual and time-consuming process for ongoing social listening reporting. Without quantitative data, it is difficult to measure the overall platform viability and trends over time accurately.
Solution
We have developed a system for mining and analyzing LinkedIn data. It consists of several components and processes that facilitate automation and standardization:
- Keyword Research and Classification. We conducted research and compiled a list of keywords and keyphrases for each area of therapy within each focus area (e.g., Transcatheter Valve Solutions, Structural Heart) in the cardiovascular landscape. These keywords and keyphrases can be used to search LinkedIn post content (e.g.,TMVR,Structuralheart,TEER). Each keyword and keyphrase is linked to its respective area of therapy and parent focus area in a database. URLs, and other metadata, including visual media, from LinkedIn posts that appear on a search result feed.
- Data Cleaning, Preparation, and Standardization. We used tools like OpenRefine along with regular expressions to develop a “recipe” that preprocesses and tokenizes the text/copy of the scraped LinkedIn posts. This returns a list of tokenized words, allowing us to determine key metrics such as top hashtags by their frequency using a count function. We also identified the top keywords across each competitor by comparing tokens to the names of products, trials, and therapies specific to each company. Numerical data, dates, and URLs were also converted or standardized to a measurable format.
- Data Dashboard. We have developed and deployed a live dashboard on Looker Studio (formerly Google Data Studio). This enables data visualization and exportation in various formats, and establishes a reporting baseline.
Requirements
- Standard LinkedIn Account
- Chromium-based internet browser
- Preferred: Arc Browser
- Backup option: Brave or Chrome
- Custom stylesheet plugin
- If using Arc, use its built-in Boosts feature and install my custom boost
- For other browsers, use an extension like StyleBot and add the following code:
section.scaffold-layout-toolbar {
display: none
}
header.global-nav.global-alert-offset-top.global-nav--visible {
display: none;
}
div.global-nav__a11y-menu {
display: none;
}
aside.scaffold-layout__aside {
display: none;
}
div.pv4.display-flex.align-items-center {
display: none;
}
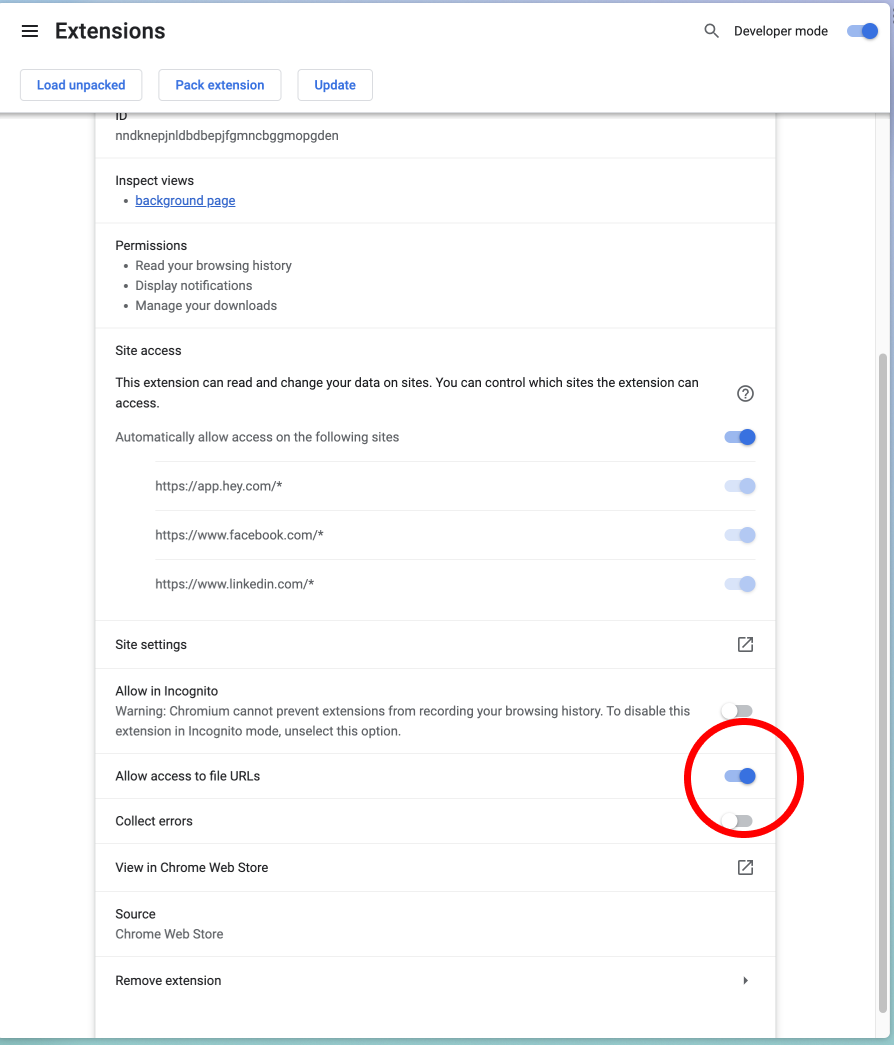
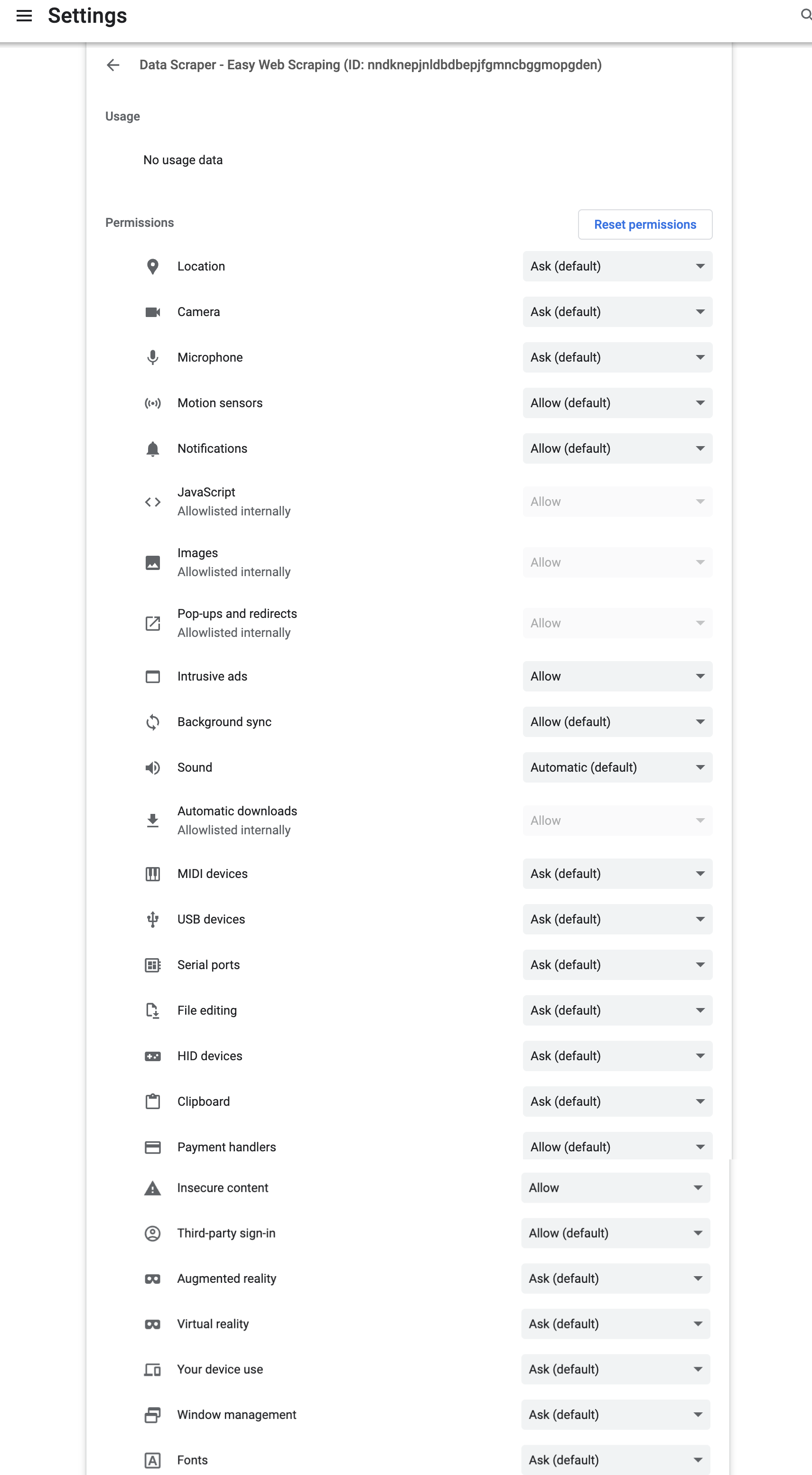
- Data Scraper chromium extension with all permissions enabled (see below screenshots)
- OpenRefine :
Keyword Research and Adding New Terms
If you need to add new keywords and terms, proceed with this section. Else, skip to Data Mining and Web Scraping Process.
Step 1: Access search terms
Visit the Search Terms and Scraping URLs tab in the Google Sheet.
Step 2: Keyword Research and Adding New Terms
- Add new search terms to the
Search Termcolumn highlighted in yellow. One term can be entered per row. A search term can be a combination of hashtag, keyword and/or keyphrase—standalone hashtags are preferred. - Add the corresponding
TopicandTherapy Areain the columns highlighted in blue. - The
Lowercase Search TermandEncoded Termcolumns are hidden by default and locked—ignore these. - Then add the corresponding topic and therapy area
- The
Search URLcolumn contains the auto-populated search URL based on theSearch Termyou provided. You will use this in the first step under Data Mining and Web Scraping Process.
Data Mining and Web Scraping Process
Step 1: Perform a Scrape
Ensure that you have met the above Requirements before proceeding. The steps and screenshots assume you are using the Arc Browser; however the process is similar if you are using Google Chrome.
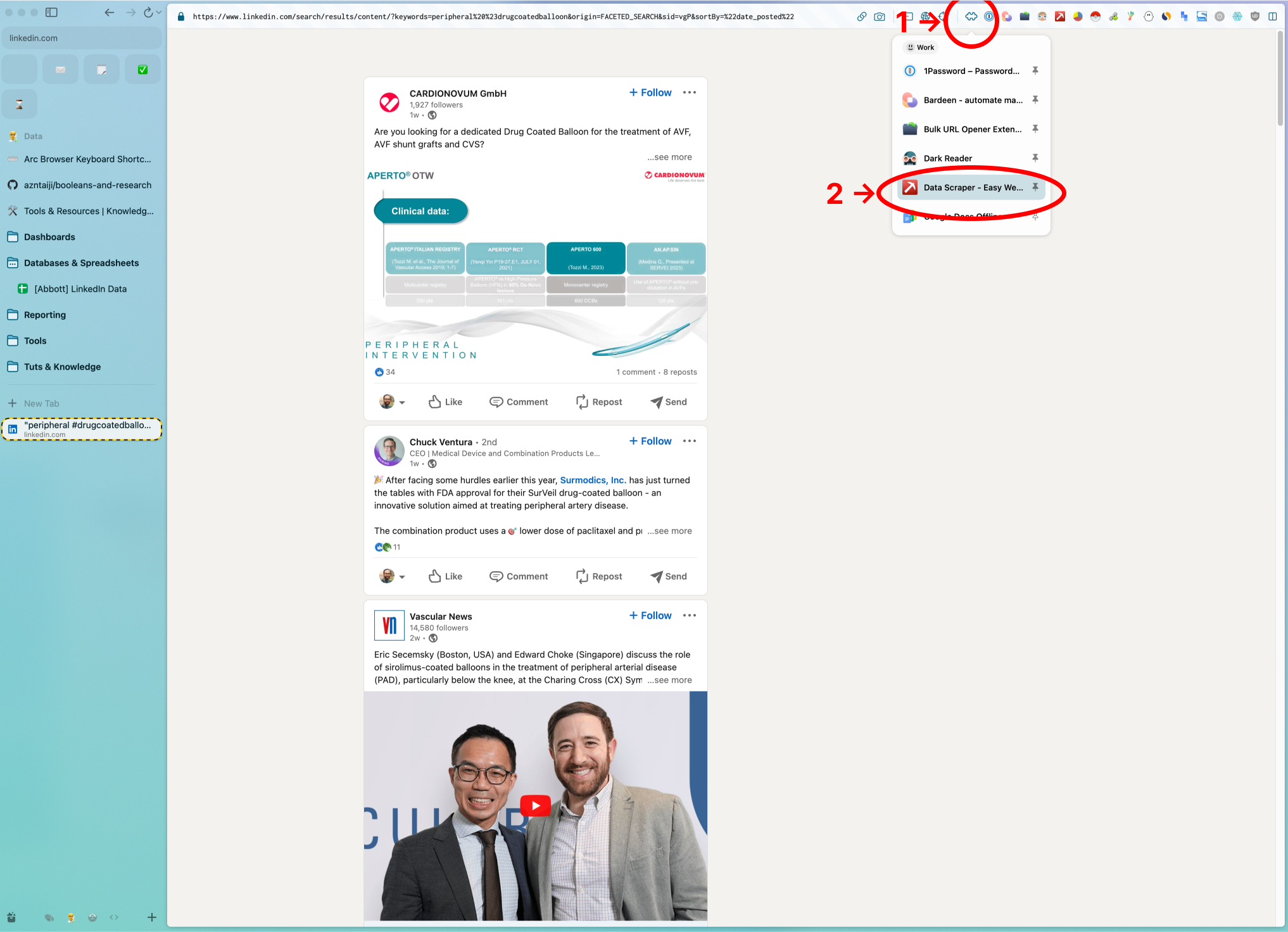
- Click on a
Search URLfrom the Google Sheet that you want to scrape to open a LinkedIn search result feed in your browser. Then open the Data Scraper extension following the below steps:
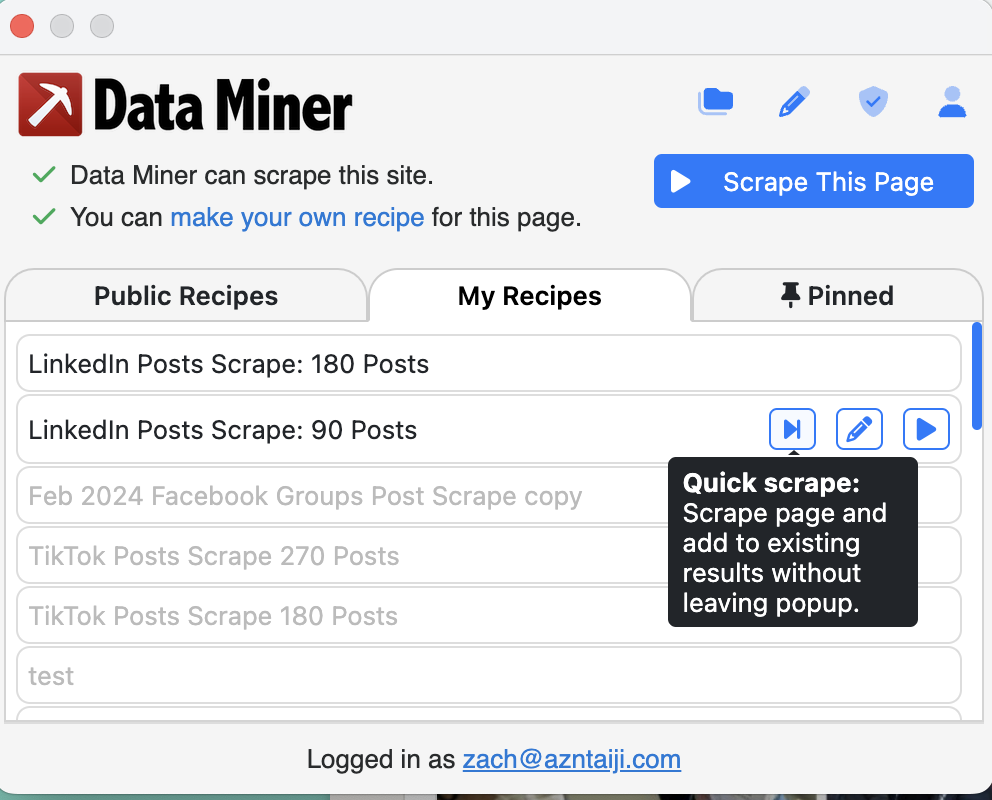
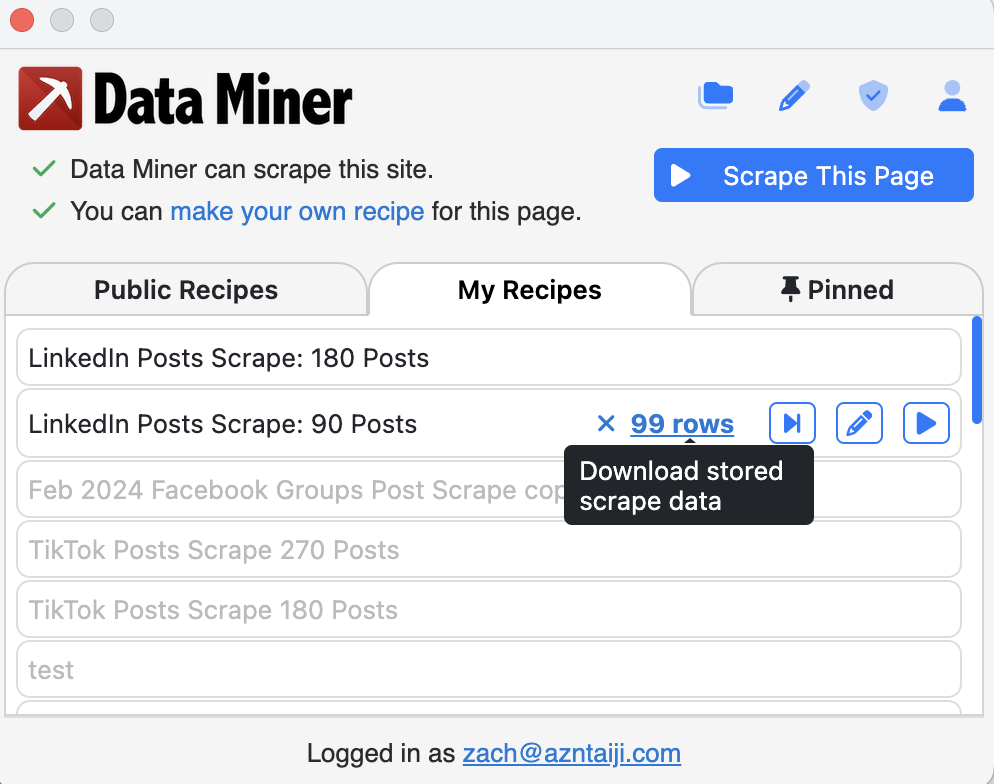
- In the Data Miner popup, goto My Recipes and then select the
LinkedIn Posts Scrape: 90 PostsorLinkedIn Posts Scrape: 180 PostsScrape.
- Download the scraped data once it is done scraping:
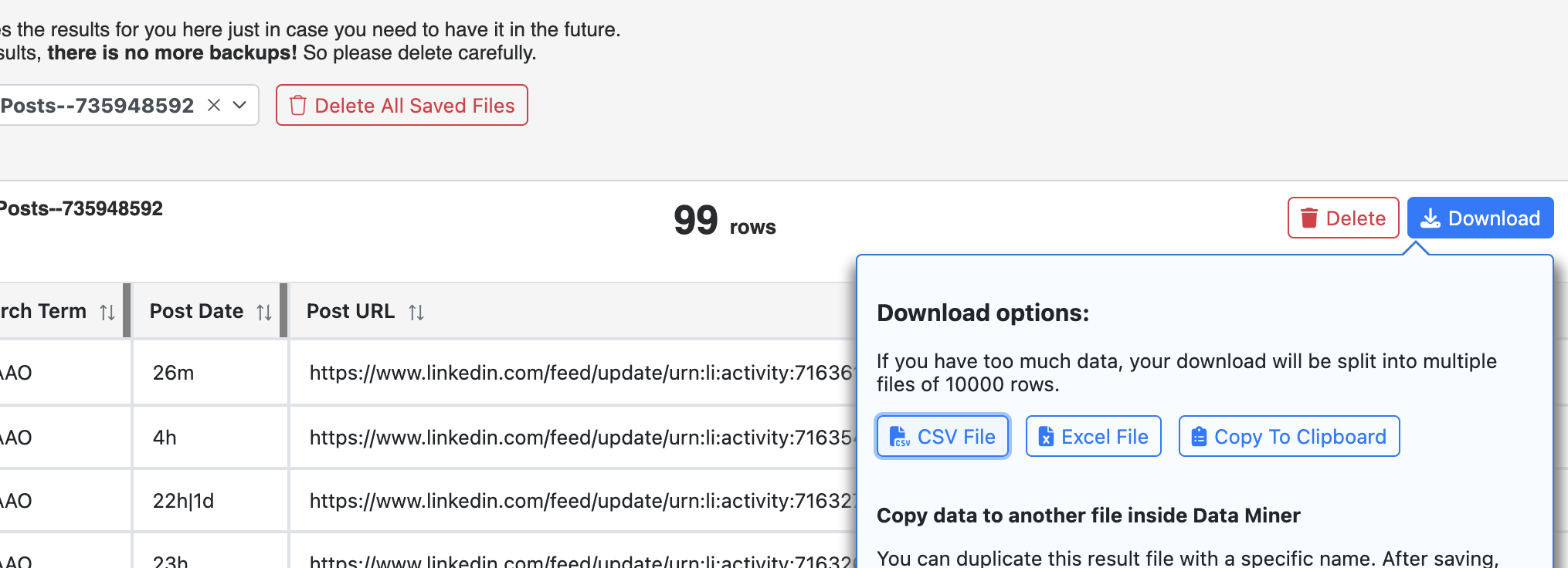
Note: You can use the single scrape method again as needed for a different search term (steps 1-2), and the results will be appended to the previous scrape. Then follow step 3 to download all of the data from multiple scrapes.
Step 2: Combine Data
- If you did multiple scrapes and therefore have more than one CSV/XLSX file, combine them into one before moving onto the next process.
Data Cleaning, Preparation, and Standardization
Step 1: OpenRefine
-
Open OpenRefine
-
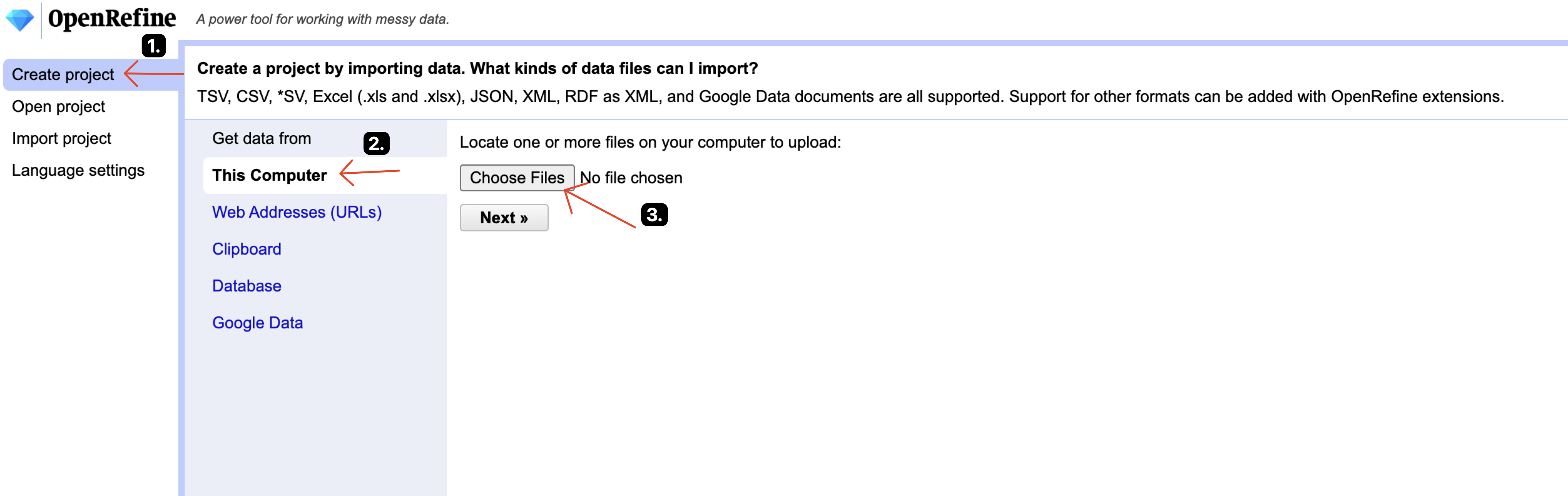
Create a new project by uploading your recently exported XLSX/CSV file:
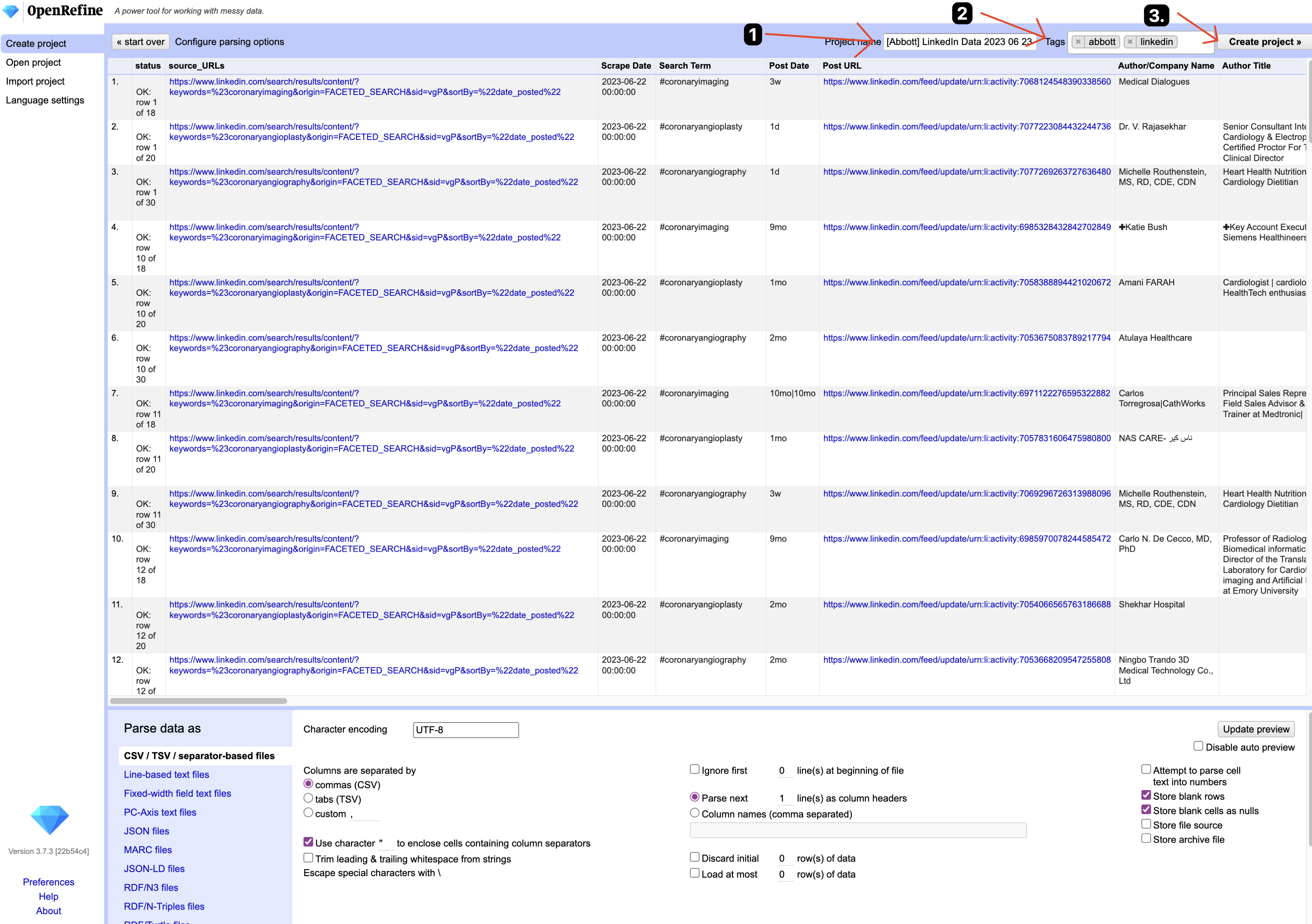
- Name project, add tags, then create project:
- Apply contents from this file to the project:
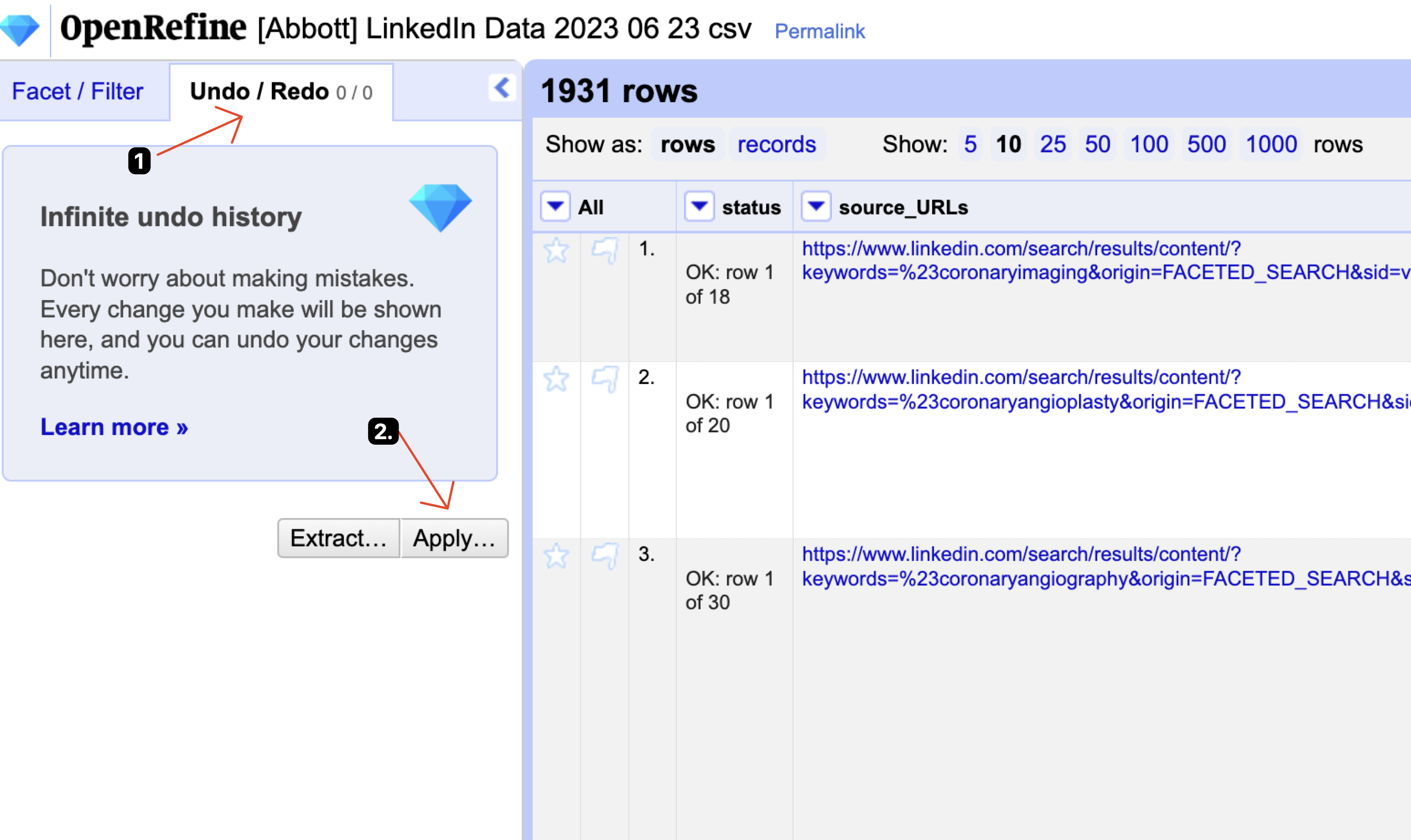
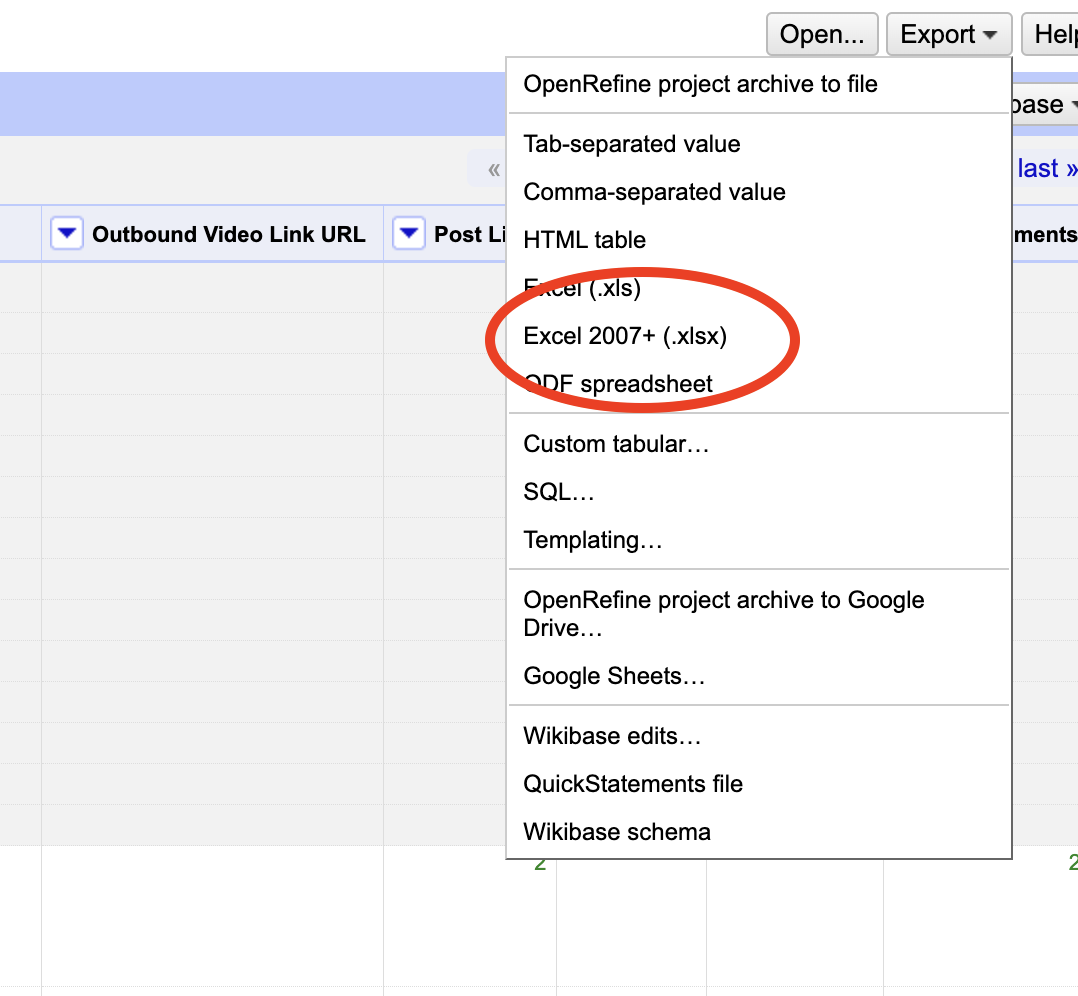
- Wait, it will take awhile to process. Then export as CSV:
Import Data Into Quid
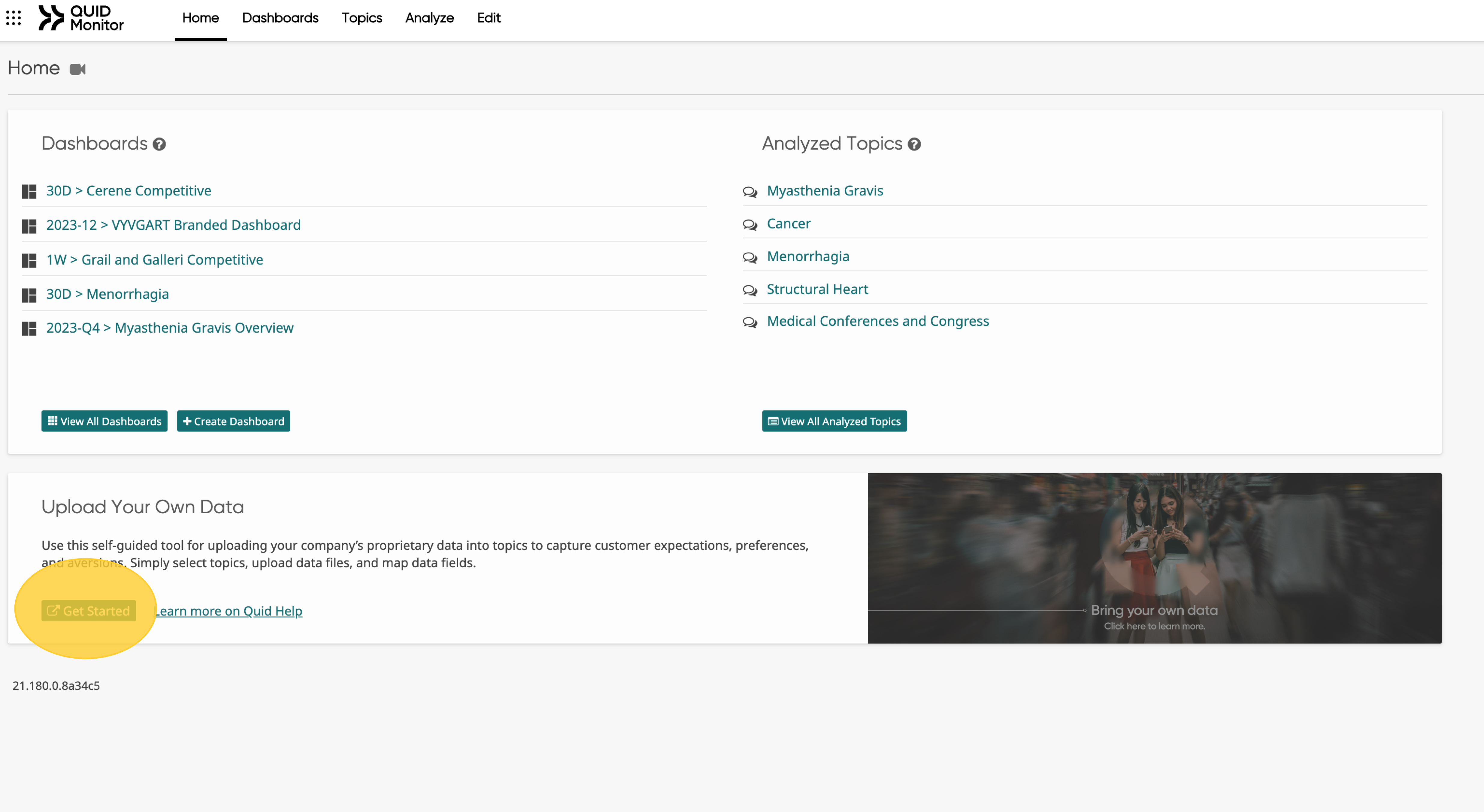
-
Goto the data uploader in Quid from the main page:
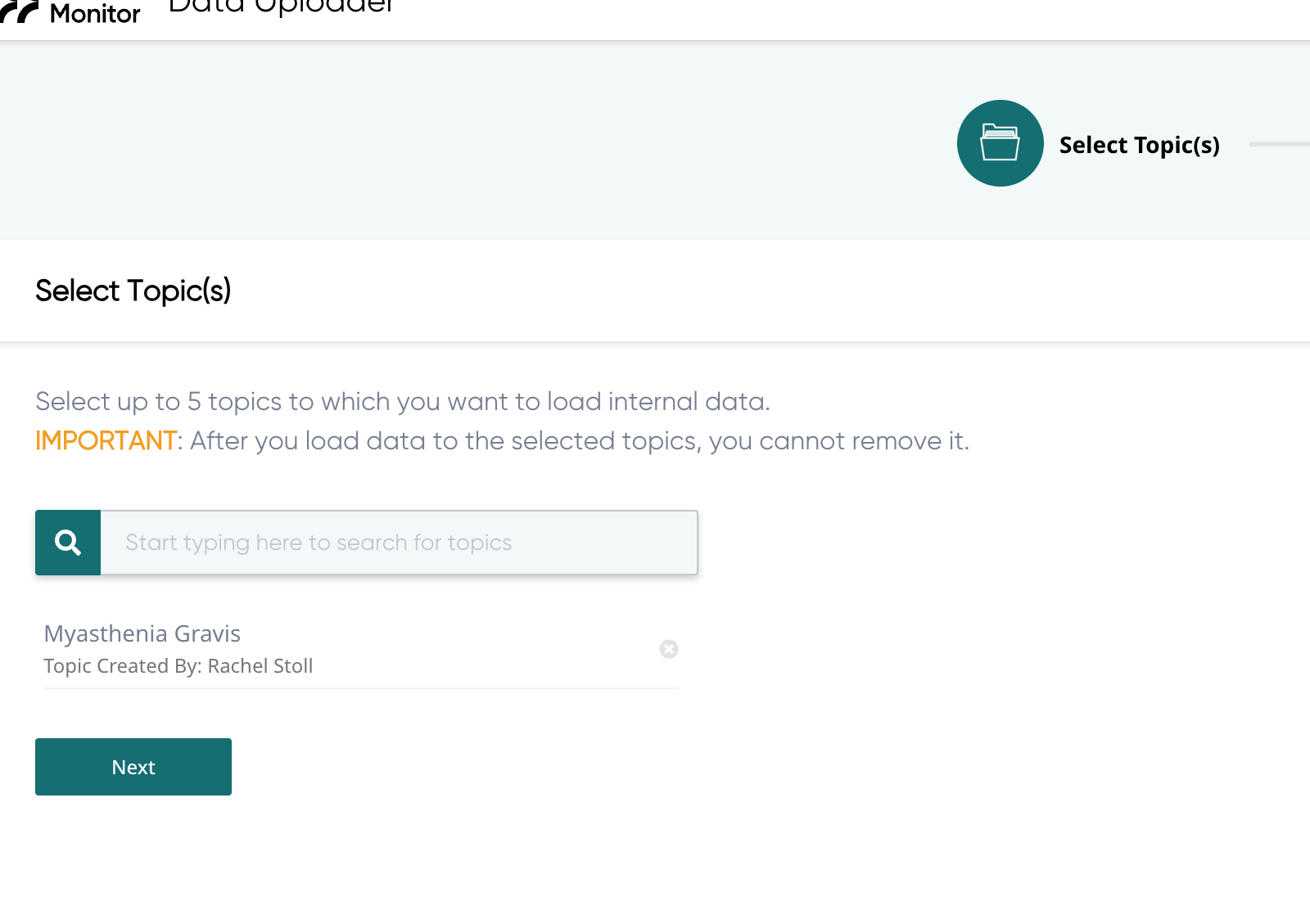
-
Select topic to upload to:
-
Upload the CSV file you downloaded from OpenRefine.
-
Click Next, Confirm, and Confirm.
-
Select the
V2 LinkedIn -
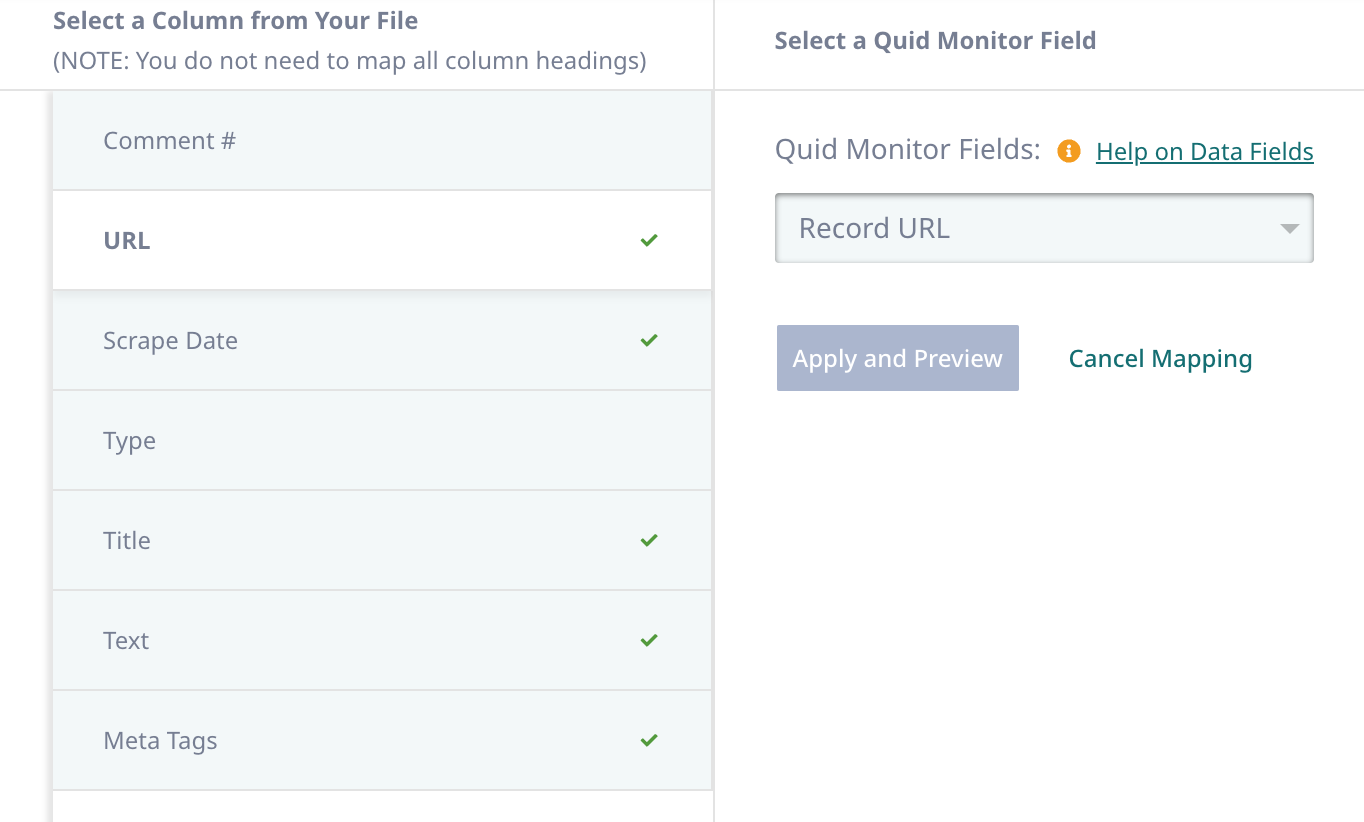
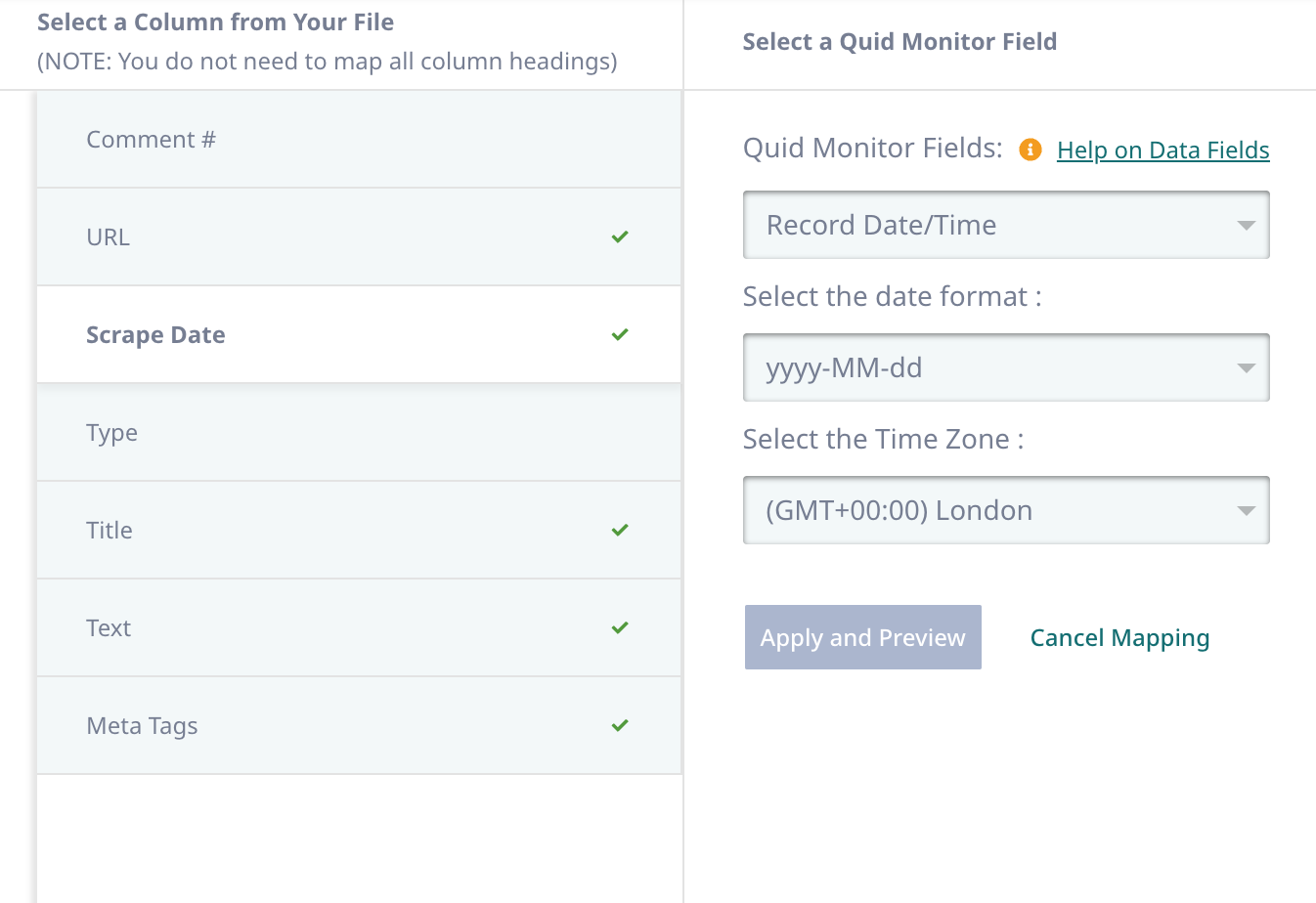
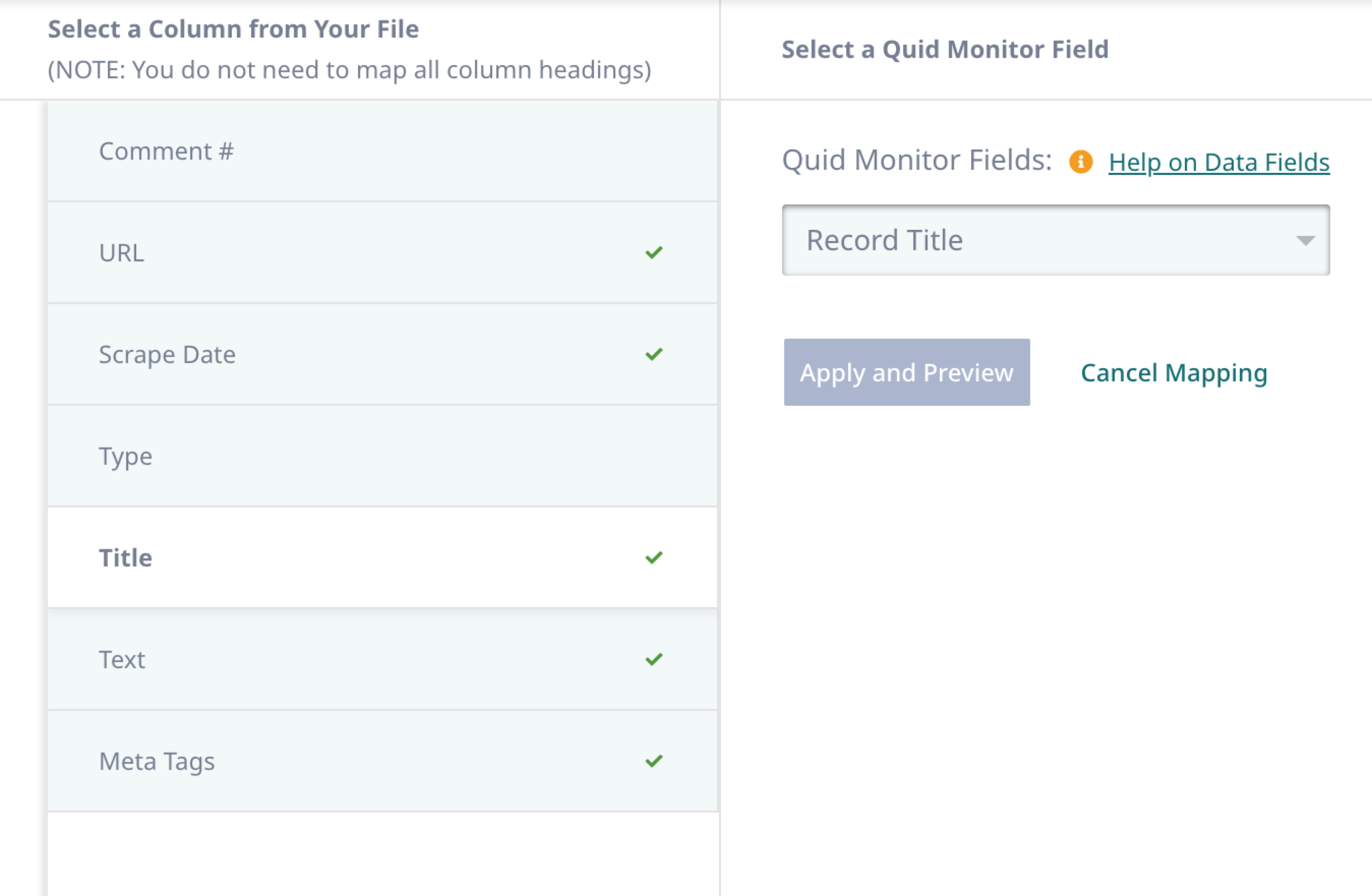
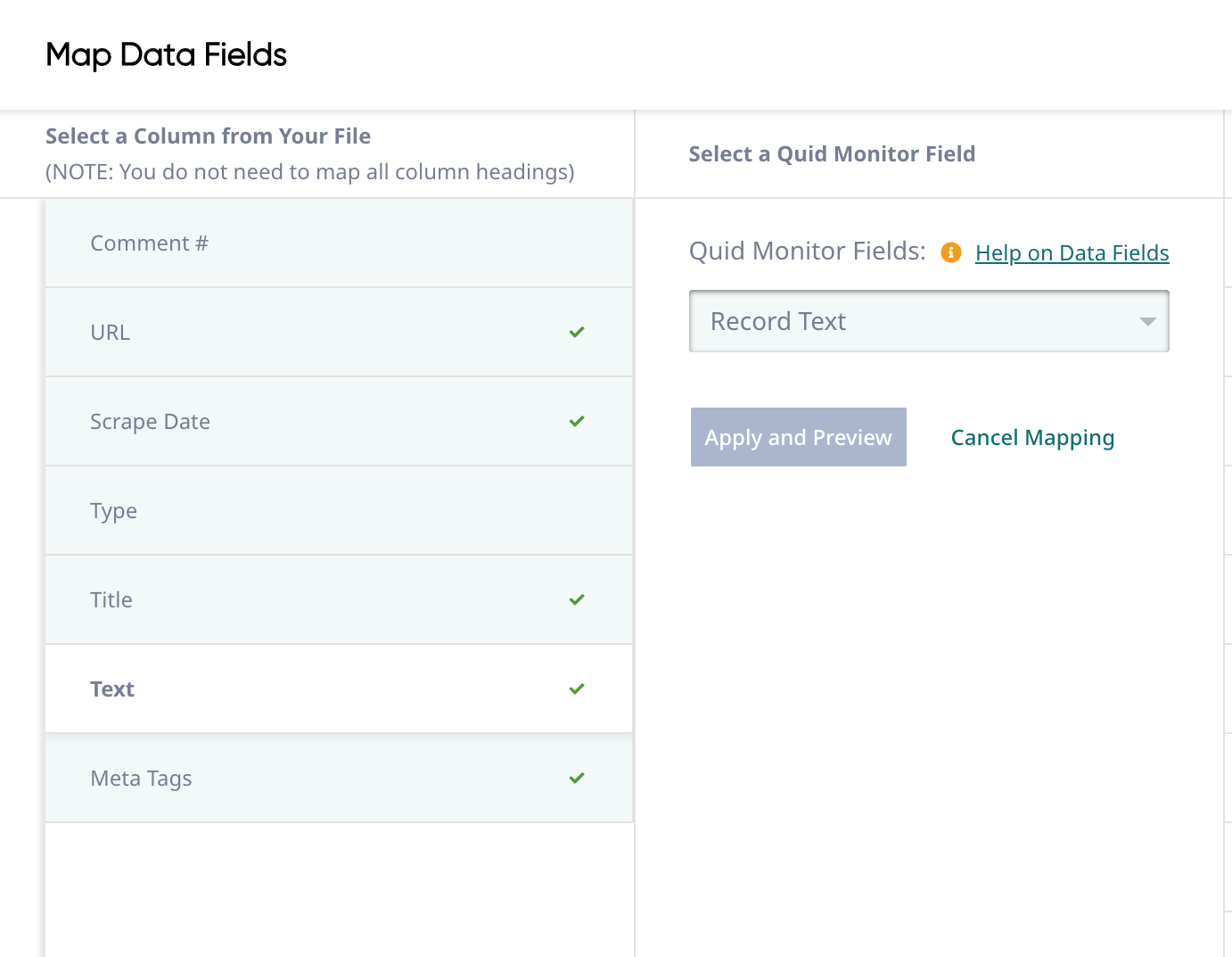
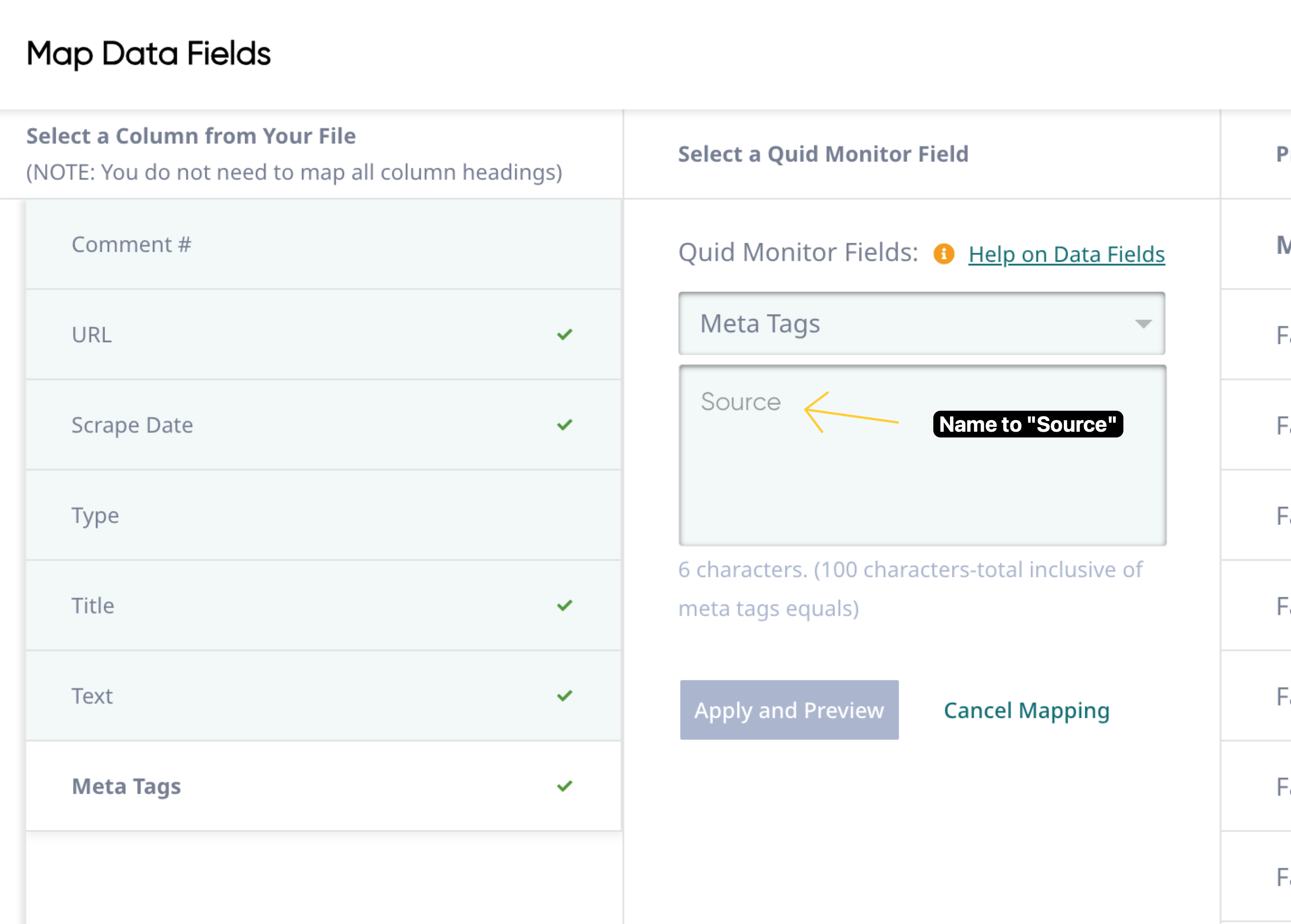
If needed, map the appropriate fields, the click Save and Verify.
-
Click Apply Mapping, then Confirm.
-
Done!
Analyze and Apply Sentiment
The following steps outline how to review and apply sentiment to LinkedIn posts for reporting.
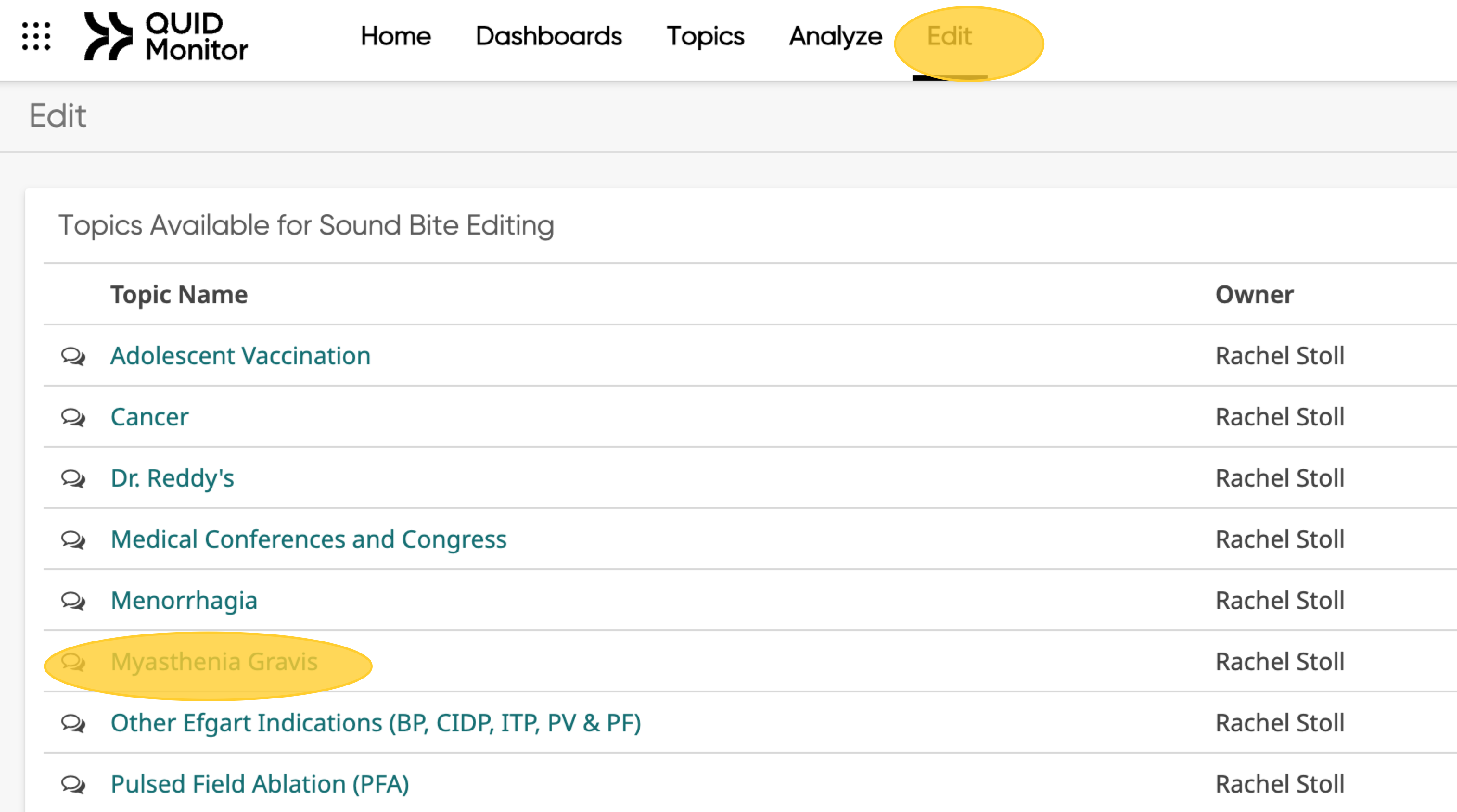
- Goto Edit on the top, then click on Myasthenia Gravis.
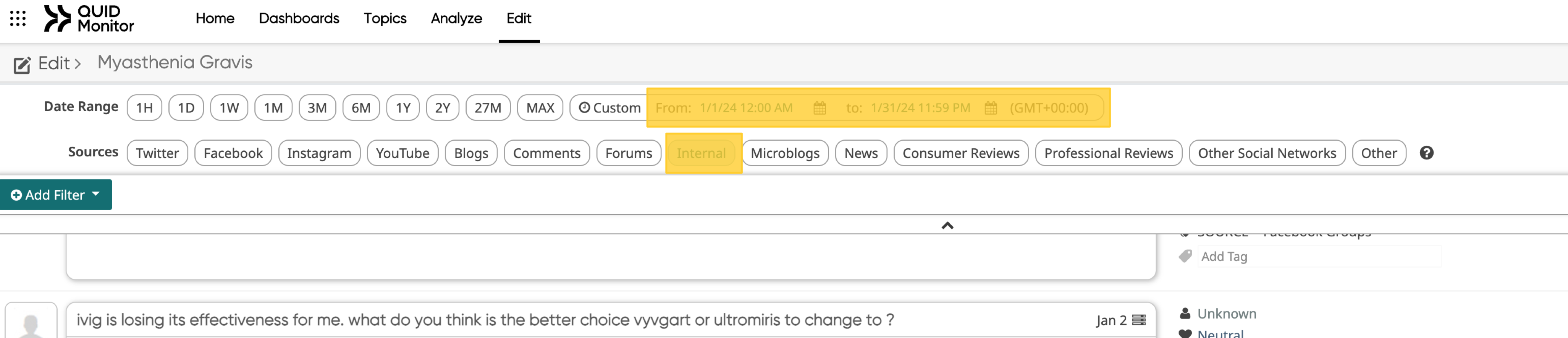
 2. Select month date range and source “internal” then click Apply
2. Select month date range and source “internal” then click Apply
 Can further drill down to Vyvgart themes:
Can further drill down to Vyvgart themes:

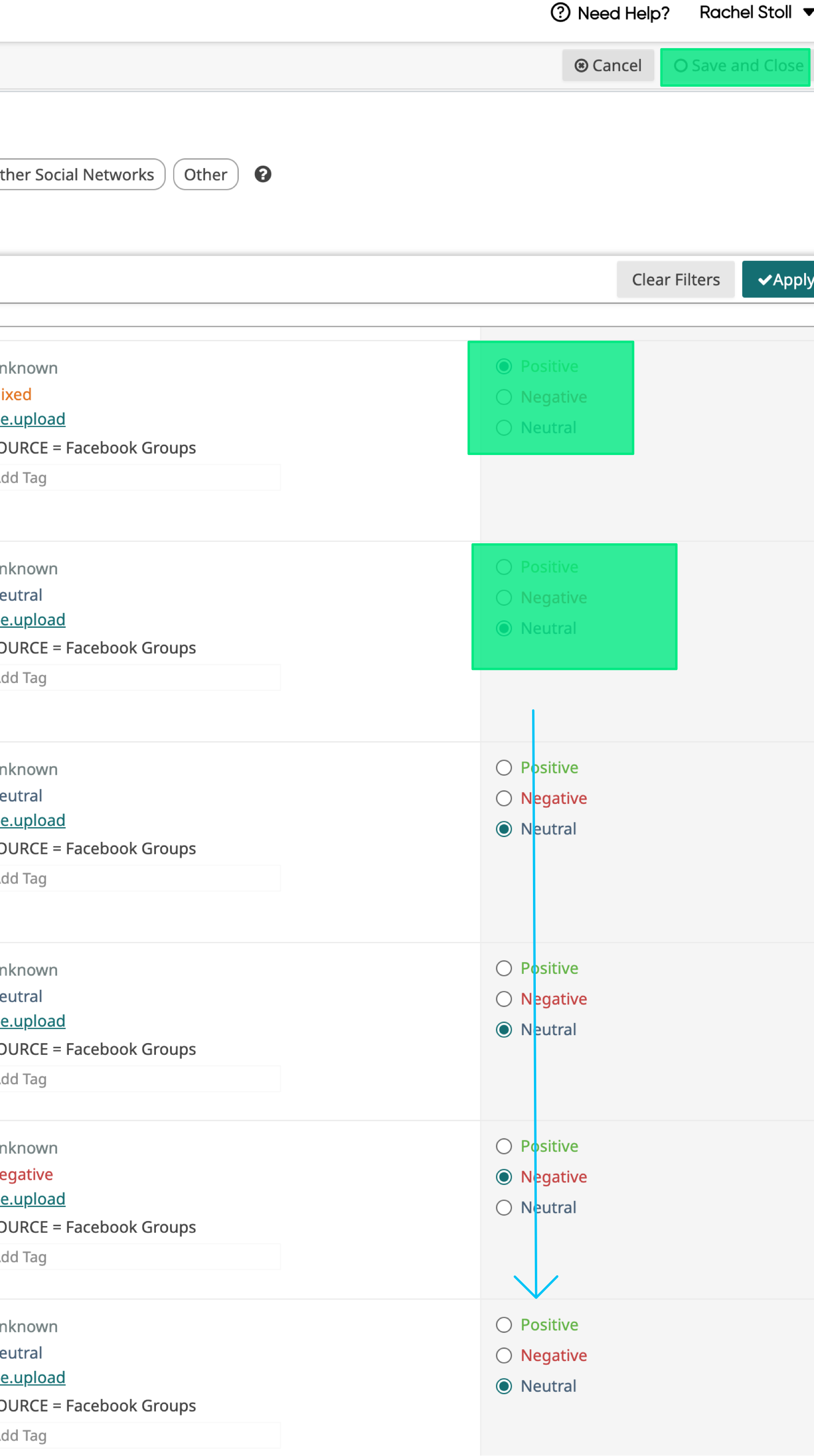
- Assign sentiments, then Save and Close:
Changelog
- 2024-02-14
- Updated Data Miner recipe, OpenRefine recipe, and added steps to ingest data into Quid
- 2023-12-30
- Updated Data Miner recipe